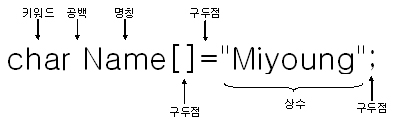사람이 쓰는 자연어에는 명사, 동사, 형용사 같은 품사가 있다. 각 품사별로 고유한 특징이 있고 품사별로 올 수 있는 위치나 단어를 조합하는 방법이 달라진다. 예를 들어 명사, 대명사는 주어가 될 수 있고 형용사, 부사는 다른 품사를 수식한다. 이런 품사들의 위치나 자격에 대한 규칙이 바로 문법이며 문법에 의해 어디가 왜 틀렸는지 알 수 있고 어떻게 수정해야 하는지도 알게 된다. 다음 예를 보면 문법에 의해 언어에 질서가 부여되고 언어가 간단 명료해짐을 알 수 있다.
■ 아가야 씩씩한 자라다오 : '씩씩한'의 품사는 형용사이며 주로 명사를 수식한다. 동사를 수식하는 것은 부사이므로 '씩씩하게'라고 고쳐야 옳다.
■ 씩씩하게 군인들이 싸운다 : 명사를 수식하는 것은 형용사이므로 '씩씩한'이라고 해야 한다. 또는 수식어와 피수식어는 최대한 인접해야 하므로 '군인들이 씩씩하게 싸운다'로 수정할 수도 있다.
키워드(Keyword)
C언어 자체가 의미를 미리 정해 놓은 단어들이며 예약어(Reserved word)라고도 한다. C언어가 이미 사용하고 있는 단어들이므로 다른 목적으로 사용할 수 없다. 즉, 키워드와 똑같은 이름의 변수나 함수를 만들 수 없다. 만약 키워드와 같은 이름의 변수를 사용하면 컴파일러는 이것을 변수로 인식하지 않고 키워드로 인식하므로 변수의 역할을 할 수 없을 것이다.
C언어의 키워드에는 다음과 같은 것들이 있는데 보다시피 그렇게 수가 많지는 않다. C는 함수 위주의 언어이기 때문에 대부분의 기능을 함수로 정의하고 있으며 따라서 다른 고급언어에 비해서는 키워드가 아주 적은 편이다.
auto, case, cdecl, const, char, continue, default, do, double, else, enum,
extern, float, for, goto, if, int, long, register, return, short, signed,
sizeof, static, struct, switch, typedef, union, unsigned, void, volatile,
while
각 키워드의 의미에 대해서는 차차로 배우게 될 것이다. 다음은 C++ 언어에서 새로 추가된 키워드들인데 주로 클래스와 관련된 것들이다.
asm, class, delete, friend, inline, mutable, new, operator, private,
protected, public, template, this, virtual, explicit, ....
이 외에도 각 컴파일러별로 추가로 제공하는 키워드들이 몇 가지 더 있는데 사용 빈도가 높지 않거나 예제 수준에서는 사용할 경우가 거의 없으므로 표준 키워드 목록 정도만 알아 두면 된다. 14882 표준 문서에는 총 63개의 키워드가 정의되어 있다.
명칭(Identifier)
명칭은 사용자가 직접 만들어서 사용하는 것이다. 변수나 함수같은 것들은 다른 것들과 구분(Identify)되어야 하므로 자기만의 고유한 이름을 가져야 한다. 만약 두 변수가 같은 이름을 가진다면 컴파일러가 이 변수들을 구분하지 못하는 애매함이 생기므로 제대로 컴파일되지 않을 것이다. 디렉토리의 파일들이 고유의 이름을 가져야 하는 것처럼 모든 명칭은 고유한 이름을 가져야 한다.
명칭은 사용자가 직접 정의하는 것이므로 이름을 자유롭게 붙일 수 있다. 입력하기 편리하도록 적당한 길이의 명칭을 작성하는 것이 좋고 최대한 의미를 기억하기 쉽도록 만드는 것이 좋다. 예를 들어 점수를 기억하는 변수라면 Score, 합을 계산하는 함수라면 GetTotal 등과 같이 이름을 붙이면 된다.
그러나 사용자가 이름을 붙인다고 해서 아무렇게나 명칭을 작성할 수 있는 것은 아니다. 하드 디스크의 파일명도 사용자가 마음대로 붙이는 것이지만 콜론이나 따옴표, 역슬레쉬 등 예약된 기호는 쓸 수 없다. 탐색기로 직접 테스트해 보면 Report:C.txt 따위의 이름은 거부된다. 이와 마찬가지로 명칭 작성에 대해서도 몇 가지 간단한 규칙이 있다. 중요한 규칙이기는 하지만 상식적인 수준에서 쉽게 이해가 가는 규칙들이다.
① 키워드는 쓸 수 없다. 키워드는 언어 자체가 이미 사용하고 있는 단어이기 때문에 명칭으로 사용해서는 안된다. int, if, while 같은 단어는 그 의미가 미리 정해져 있다.
② 알파벳, 숫자, 밑줄기호(_)로 구성된다. 그 외의 콜론, 따옴표, 괄호 같은 기호는 명칭으로 쓸 수 없다. 한글도 알파벳이 아니므로 명칭으로는 사용할 수 없다. 명칭 중간에 공백이 와서도 안된다.
③ 첫 문자는 알파벳이나 밑줄기호만 올 수 있다. 숫자는 명칭의 중간에는 올 수 있지만 처음에는 오지 못한다. Num1, Inch2Cm은 적합한 명칭이지만 3D, 4you 같은 명칭은 숫자가 앞에 있으므로 적합한 명칭이 아니다.
④ C언어는 대소문자를 구분한다. 따라서 Score, score, SCORE는 철자는 같지만 모두 다른 명칭으로 인식된다. 명칭의 대소문자 구성은 가급적이면 일관되게 작성하는 것이 좋다. 예를 들어 모두 소문자로 작성하거나 아니면 첫 문자만 대문자로 쓰는 것이 좋다.
Korea, Score2, My Score, z, c:\, kkk, Total_Student, _line
Korea는 예약어가 아니므로 적합한 명칭이다. Score2도 숫자가 첫 부분에 있지 않으므로 역시 적합한 명칭이다. 그러나 My Score는 중간에 공백이 들어갔으므로 명칭으로 쓸 수 없다. 두 개의 단어로 명칭을 만들고 싶을 때는 MyScore처럼 두 단어를 붙여 쓰거나 아니면 밑줄기호를 사용하여 My_Score로 쓰는 것이 일반적이다.
z는 비록 한 글자로 되어 있지만 이것도 적합한 명칭이다. 명칭의 길이에 대해서는 특별한 제한이 없으므로 한 글자로 쓸 수도 있고 아주 길게 쓸 수도 있다. 그러나 너무 길면 입력하기 불편하며 또 너무 짧으면 의미를 기억하기 어려우므로 적당한 길이의 이름을 붙이는 것이 좋다. a, b, kkk 같은 명칭은 가능하기는 하지만 별로 바람직하지는 않다. c:\는 명칭에 쓸 수 없는 콜론, 역슬레쉬 등의 기호가 중간에 들어 있으므로 명칭으로 사용할 수 없다. Total_Student나 _line은 둘 다 명칭으로 사용 가능하다.
명칭이란 쉽게 말해서 변수나 함수 등에 원하는 이름을 붙이는 것이다. 이렇게 작성한 명칭으로 변수, 함수, 레이블, 타입 등을 만드는데 각각에 대해서는 관련장에서 하나씩 배우게 될 것이다. 여기서는 명칭 작성 규칙에 대해서만 알아 두도록 하자.
상수(Constant)
변수의 반대되는 개념이며 고정된 값을 가지는 식이다. 5, 638, 1.414 이런 것들이 상수이다. 5는 언제까지나 5일 뿐 그 값이 변하지 않으므로 분명히 상수이다. 숫자 상수외에 문자 상수, 문자열 상수도 있다. 문자 상수는 홑따옴표로 감싸 'A', '8' 등과 같이 표현하고 문자열 상수는 "Korea"와 같이 겹 따옴표로 감싼다.
연산자(Operator)
계산을 지시하는 기호들을 연산자라고 한다. 실생활에서 많이 사용하는 +, -, *, / 같은 사칙 연산자들도 있고 이외에 관계, 대입, 논리 연산자 등 다양한 연산자가 있다. 또한 C 언어만의 고유한 포인터 연산자, 삼항 연산자 등 나름대로 복잡한 연산자들도 많이 있는데 연산자에 대해서는 5장에서 따로 상세하게 배울 것이다.
구두점(Punctuator)
자연어에는 마침표, 쉼표, 물음표, 느낌표같은 것들이 있어서 단어들을 구분하고 뜻을 좀 더 분명히 전달하는 역할을 한다. C언어도 마찬가지로 구성 요소를 구분하여 좀 더 분명한 의미를 가지도록 하는 구두점이 있다. 쉼표, 따옴표, 괄호, 세미콜론 등이 구두점으로 사용된다.
공백 문자(White Space)
스페이스와 탭, 개행 코드 등이 공백이다. 공백 문자는 눈에 보이지 않지만 구성 요소들을 구분하는 아주 중요한 역할을 한다. int num;이라는 선언에서 int라는 키워드와 명칭 num이 공백에 의해 분리되어 있다. 만약 공백이 없다면 intnum;이 되어 버리므로 컴파일러는 어디까지가 키워드이고 어디서부터 명칭인지를 구분하지 못할 것이다. 주석도 일종의 공백으로 인정된다.
주석(Comment)
설명을 위해 삽입되는 문자열이다. 컴파일러는 주석을 완전히 무시하므로 프로그램 실행에는 아무런 영향을 주지 않는다. 주석은 소스를 읽는 사람이 의미를 쉽게 파악할 수 있도록 설명을 붙여 놓는 것이다. 좀 어려운 부분이거나 추가 작업이 필요한 부분 등에 대해서는 주석으로 간단한 설명을 달아 놓을 수 있다.
주석은 /*로 시작해서 */로 끝나거나 한줄내에서만 주석을 쓰고 싶을 때는 //를 사용한다. 구형 C 컴파일러는 /* */만 주석으로 인정하지만 최신 컴파일러들은 모두 //도 주석으로 인정한다. 주석은 어디까지나 문자열일 뿐이므로 한글이나 기호 등도 자유롭게 사용할 수 있다. 다음이 주석의 예이다.
/* 별표를 사용하여 삼각형을 출력하는 놀라운 예제
만든 사람 : 김 상형 */
#include <stdio.h>
void main()
{
int i,j;
for (i=1;i<=15;i++) {
for (j=0;j<i;j++) {
printf("*"); // 별표 하나를 출력한다.
}
printf("\n"); // 한줄이 끝나면 개행한다.
}
}
주석은 또한 설명을 달아 놓는 용도 외에도 코드를 임시적으로 삭제할 때도 사용한다. 잠시만 코드를 없애 보고 싶다면 이 부분을 지우는 대신 주석으로 묶어 두면 된다. 컴파일러는 주석을 무시하므로 주석으로 묶어 놓은 부분은 없는 코드와 마찬가지가 되며 실제로 지운 것은 아니므로 이 코드가 다시 필요할 때 주석을 풀기만 하면 된다.
이상으로 C언어를 구성하는 일곱 개의 구성 요소에 대해 알아보았다. 모든 C 코드는 이 일곱 개의 구성 요소들로 이루어진다.